blog 插件记录
用不惯 mk 这个 blog 插件,这个 tap 不打算维护了。感兴趣的内容看首页或者分类吧。
用不惯 mk 这个 blog 插件,这个 tap 不打算维护了。感兴趣的内容看首页或者分类吧。

组件说明
执行流程说明:
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy也会重新下载。)
hprof文件是一种Java堆转储文件(二进制文件),用于分析和诊断Java应用程序的内存使用情况。它包含了Java堆中的对象信息,包括对象的类型、大小、引用关系等。通常情况下,.hprof文件是由Java虚拟机(JVM)生成的,用于记录应用程序在某个时间点的内存快照。
.hprof文件可以提供有关应用程序内存分配、对象泄漏、内存使用量等方面的详细信息。通过分析.hprof文件,开发人员可以确定内存中的对象数量、对象类型、对象之间的引用关系,以及哪些对象可能占用了大量内存或存在内存泄漏的风险。
下面介绍几种获取jvm 堆快照的方法。
目前使用基于netty的tcp长连接处理电梯秒级数据。
具体来说是处理电梯的modbus报文,这个主从协议要求获取设备的数据需要主动下发命令来触发上报。在频繁的报文接收、处理及发送中,内存泄漏叻。
一般内存泄漏主要表现在服务器内存爆满,某个类实例数特别多、占有内存特别多,GC到不行时服务器自动重启,当然最明显的就是会有leak报错(确定服务器崩的大概时间点,翻下error日志,你会找到的),比如下面这样:
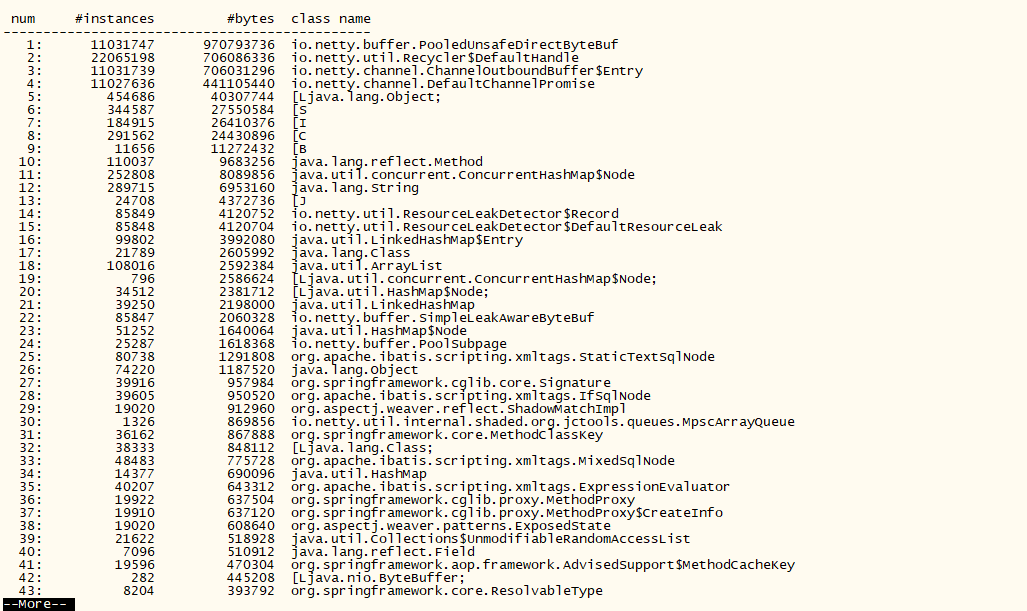
很久之前写的,刚好最近又用到 https://blog.shafish.cn/archives/1670/
安装好然后虔诚地按下电源开关。
sudo smartctl -i /dev/sda
=== START OF INFORMATION SECTION ===
Model Family: Western Digital Red
Device Model: WDC WD40EFRX-68NxxNx
Serial Number: WD-WCC7K4FXPxxR
LU WWN Device Id: 5 0014ee 211f4dd29
Firmware Version: 80.00A80
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5400 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Thu Jan 14 22:45:01 2021 CST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
location /
{
...
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
...
}

https://www.youtube.com/watch?v=5ce-CcYjqe8 https://www.youtube.com/watch?v=BoMlfk397h0&t=915s https://www.youtube.com/watch?v=_JTEsQufSx4 https://gitlab.com/risingprismtv/single-gpu-passthrough/-/wikis/1
# 更新:
nano /etc/apt/sources.list.d/pve-enterprise.list
# 注释掉 deb https://enterprise.proxmox.com/debian/pve stretch pve-enterprise
echo "deb http://download.proxmox.com/debian/pve stretch pve-no-subscription" > /etc/apt/sources.list.d/pve-install-repo.list
gpg --keyserver keyserver.ubuntu.com --recv-keys 0D9A1950E2EF0603
gpg --export --armor 0D9A1950E2EF0603 | apt-key add -
apt update
echo "options vfio-pci ids=10de:2486,10de:228b disable_vga=1" > /etc/modprobe.d/vfio.conf
nano /etc/modprobe.d/blacklist.conf
blacklist nouveau
blacklist radeon
blacklist nvidia
nano /etc/modprobe.d/kvm.conf
options kvm ignore_msrs=1
update-initramfs -u
reboot
shafish docker hub
或者直接安装官网安装:https://docs.docker.com/engine/
yum install -y yum-utils
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum install docker-ce docker-ce-cli containerd.io docker-compose-plugin
# https://wiki.archlinux.org/title/Docker
sudo pacman -S docker docker-compose
yay -S docker-rootless-extras
sudo echo "your_username:165536:65536" > /etc/subuid
sudo echo "your_username:165536:65536" > /etc/subgid
sudo systemctl enable docker
sudo systemctl start docker
export DOCKER_HOST=unix://$XDG_RUNTIME_DIR/docker.sock